Features Engineering > Dimensionality Reduction > Principal Component Analysis
Published on 2024-02-09
Data ScienceWhen dealing with high dimensional data (known as The Curse of Dimensionality), it is often useful to reduce the data size for efficient computation. One such method, also very popular method, is Principal Component Analysis.
When gathering data or utilizing a dataset, identifying the crucial variables isn't always straightforward or intuitive. There's no assurance that the variables chosen or provided are indeed the most relevant ones. Moreover, in the age of big data, datasets often contain an overwhelming number of variables, leading to confusion and potential misinterpretation.
Principal Component Analysis (PCA) is a linear unsupervised learning technique that constructs some new characteristics to summarize data. It tries to preserve the essential parts that have more variations of the data, and remove the non-essential parts with fewer variations. In other words, PCA constructs a smaller dataset from the original dataset.
In order to construct PCA, we need to (1) Prepare data (clean and standardized).
(2) Derive a covariance matrix. Why? Because we want to retain the data with the most variation. A covariance matrix provides important information about the relationships between variables in a dataset. Specifically, it tells us the degree to which two variables vary together. Positive covariance means the two variables move together in the same direction, negative covariance indicate that the two variables move in opposite directions whereas 0 covariance means there is no relation between the two variables.
Covariance Matrix is computed as:
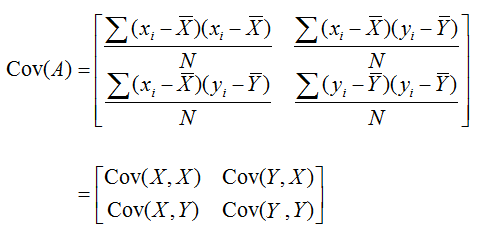 Notice the formula is similar to variance (spread of the data). Therefore, the covariance value of (X,X) is variance of X!
If the average of each data set (each column) is zero, the covariance matrix of the matrix can be calculated as follows: Matrix multiplied with Transpose of a Matrix.
Notice the formula is similar to variance (spread of the data). Therefore, the covariance value of (X,X) is variance of X!
If the average of each data set (each column) is zero, the covariance matrix of the matrix can be calculated as follows: Matrix multiplied with Transpose of a Matrix.
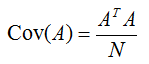 That's why we use matrix to do computation. We don't have to do the manual computation of variances! Matrix makes it easy for such computation and that's the reason why almost all the data for data analysis are put into matrix form.
Source
That's why we use matrix to do computation. We don't have to do the manual computation of variances! Matrix makes it easy for such computation and that's the reason why almost all the data for data analysis are put into matrix form.
Source
(3) From covariance matrix, perform Eigenvalue Decomposition yielding a set of EigenValues (variation along each eigenvector) and eignvectors (direction/space in which data varies the most). Eigevalue Decomposition is simply rewritte the Covariance matrix as TDT^T where T is eigen vectors, D is eigen values (in diagonals) and T^T is a transpose of T.
For "m" features with "n" data points, the maximum principal components we can have is "m". Each "m" principal component has its own eigenvector (representing the direction) and their eigenvalues (representing the amount of variance).
For visualization, I found this amazing source. I take the gif from there.

First, plot feature x and feature y to a dot plot and then imagine we draw a linear line. We want this linear line where the new data (eigen values) will reside to have maximum variance or spread. In the gif, the red dots are new data. The distance between blue and red dots is the error. We want to have the maximum variance for new set of data as we prefer highest variations for new dataset, and minimum error for reconstructions of original data from new data. This happens when the linear line is in the position of pink color (the spread of the red data is maximized and the distance from original blue to new red is minimal). This linear line space is our eigen vector or direction/space. The red dots on that linear line are eigen values!
(4) After computing "m" number of PCAs, we sort them by their eigenvalues in descending order. Because we want the highest variance! Each of the principal components will be uncorrelated with one another. The principal components with the highest eigenvalues are “picked first” as principal components because they account for the most variance in the data. Then, we choose how many PCAs we want depending on our needs.
Given a mean centered dataset X with "n" data points and "m" features, the first component PC1 is given by the linear combination of the original variables x1, x2, ..., xm.
PC1 = (w1 * x1) + (w1 * x2) + ... + (w1 * xm) where w1 = (w11, w12, ..., w1m) and w1 corresponds to an eigenvector of the covariance matrix and the elements of w1. PC2 = (w2 * x1) + (w2 * x2) + ... + (w2 * xm) where w2 = (w21, w22, ..., w2m)
The elements of w1, w2 and so on are called loadings. From loadings, we know how much a feature is contributing to PC.
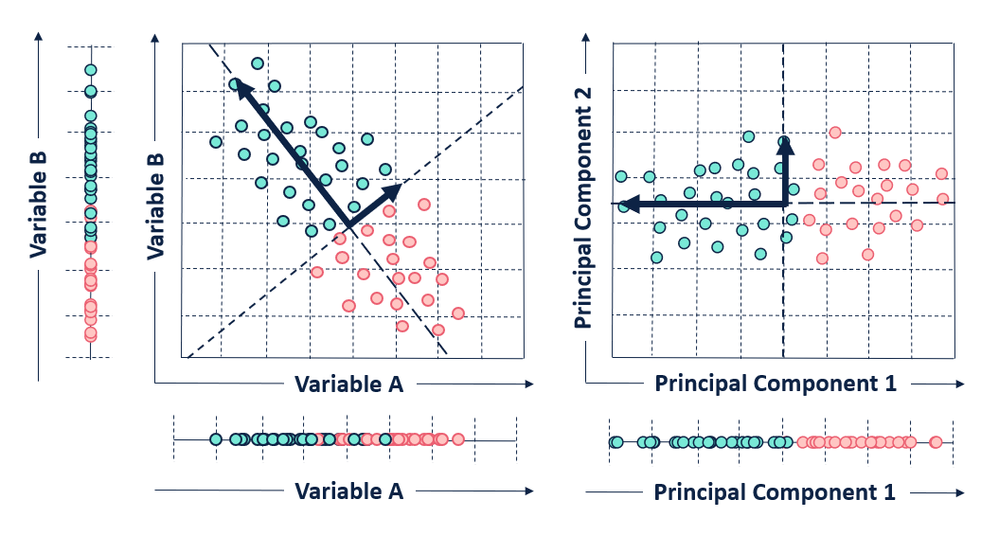
Weakness - The weakness of PCA is that it does not maintain the local topology of original dataset. For example, when points p and q are distant in the high-dimensional space, it is desirable to maintain this spatial relationship in the reduced space. However, PCA does not always achieve this preservation. - Additionally, since PCA is a linear transformation method, it does not work well with non-linear structure.
Example using sklearn for PCA It only takes a few lines to compute PCA thanks to DataScience Libraries.
from sklearn.decomposition import PCA
# Assuming X is your standardized data matrix
pca = PCA(n_components = 2) # specify the number of PCA you need. If not specify, it will take min(n_samples, n_features). Usually it's n_features
principal_components = pca.fit_transform(X)plt.scatter(pca[:0], pca[:1], c=labels) # with labels from dataset
plt.title('PCA Visualization of Dataset')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()One interesting parameter from sklearn.decomposition.PCA is explained_variances_ratio. This metric tells us how much each principal component is contributing to retain the information from the original dataset. Explained_variances_ratio = explained_variance / total_explained_variances. Obviously, the first principal component will have the highest explained_variances_ratio as the variance of it will be the greatest among all principal components.
Another important parameter is components_ or loadings. This method gives us the weightage w1 = (w11, w12, ..., w1m) for PC-1, w2 for PC-2, ..., wm for PC-m, that is, w11 = weightage of feature 1 for PC-1, so on and so forth.
References https://setosa.io/ev/principal-component-analysis/ https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html